Over the last few months I had a private tinkering side-project about an ontology design assistant that brought together a few ideas I had lately. Some for which I can already show a prototypical implementation, for others not. I recorded myself presenting it, you are most welcome to check it out if you are curious. If you are not into triple stores or graphs, it might be a bit hard to follow at times. The part that might be most understandable without previous knowledge is the wizard-example from 25:15 to 29:55, direct link to it here. Other direct links to parts are available in the repository: github.com/benjaminaaron/OntoEngine.
Update
13.1.2021
Four things as of late that I’d like to share.
Tech4Germany: Open Data Process Guide
As shared in the previous post, I was part of Tech4Germany as engineering fellow from July to October 2020. The experience was great and I highly recommend it! Currently the applications for 2021 are open! :) All 8 teams published their results on the Tech4Germany website. My team’s results – the open data process guide GUIDO – can be found here and our open source code here. A few neat ideas made their way into the code that I am really happy with and might reuse in future projects in some way or another. The base idea was to enable ministries to first assemble their own process of publishing open data based on customisable building blocks and then follow this process on a regular basis to publish open data. A cool feature we prototyped was to start the configuration of process via a BPMN diagram that ties the respective steps together in the right order. Another feature was to be able to email the files in question to GUIDO and get back a link that takes you directly into a new publishing-case for said files.

Update 8.2.2021: I was invited to write a blogpost (in German) on the GovData blog about this project. You can find it here.
Lunch matchmaking & Miro art
As most engineers in the Tech4Germany projects didn’t get to actively code until around halfway of the 12 weeks, I spent some time developing useful little things :)
The organisers intended for us to have lunch with a random person among the 32 fellows each week. This matching however, would have become increasingly hard to do manually in Excel if no one is to meet the same person twice and it should not occur for team mates to be matched since they talk enough on a daily basis. I saw a chance to apply some of the subgroup math that I have been fiddling with now and then over the last years. So I wrote a bit of code that facilitates the matching while honouring said and also newly added constraints. From week 2 onwards, it became my Monday-task to run the script and post the results in the lunch channel.
In preparation for a short presentation about the lunch matchmaking algorithm I looked up how to create and modify elements on a Miro board by code. I wanted to highlight the connection of the subgroup math to Pascal’s triangle, Sierpiński triangle and the Fibonacci spiral by having them appear on a Miro board and zooming in on them etc.

Ethereum introduction video
End of September 2020 I gave the introduction to the Ethereum Blockchain as part of the lecture “Sustainable DAOs: Blockchains, Smart Contracts and Value-Sensitive Token Design” at ETH Zürich with Dr. Marcus Dapp and Mark Ballandies. The 1.5h recording is embedded below. From 12:38 on I use eth.build from Austin Griffith for a no-code visual intro to some basics. From 31:38 on I walk through the coding and deployment of a mini dApp, using a self-built “commit walker” script to move forward in the git history. At 48:16 starts a demo of our Finance 4.0 platform and from 1:02:59 I trace the claiming of a token through the code.
Finalist in TUM Future Learning Initiative
I participated in the TUM Future Learning Initiative 2020 and, while not having won it, two of my submitted ideas were among the finalists. Going into a university-wide voting, all finalists got coaching from ProLehre and made short professional videos with their media production team. Since I was with Tech4Germany in Berlin at the time, we recorded mine via video calls. Below both videos and two PDFs for each: the initially submitted ones and the ones displayed below the videos during the voting process.
Gedanken zu Open Data und agilen Prozessen
Ich bin super glücklich darüber, als Engineering Fellow 2020 bei Tech4Germany angenommen worden zu sein. Wir haben eine wunderbar organisierte, voll gepackte und inspirierende Onboarding-Woche hinter uns und werden nun in den jeweiligen Teams in die 8 Projekte eintauchen bis Ende Oktober. Ich bin im Projekt “Open Data Portal” mit dem Auswärtigen Amt und GovData.
Ich würde gerne diesen Zeitpunkt nutzen wo ich noch nicht super tief im Projekt stecke um ein paar allgemeine Gedanken aufzuschreiben. Später ist es mir möglicherweise peinlich so rumzuphilosophieren obwohl ich nur halb Ahnung habe. Aktuell habe ich noch angenehm kaum Ahnung :)
Während der Onboarding-Woche haben wir viel wertvollen Input von Change Agents in der öffentlichen Verwaltung bekommen. Viel davon drehte sich um den Mehrwert den die Akzeptanz und Verbreitung von agilen Prozesse bringen kann. Nicht zuletzt ist Tech4Germany ja selbst eine Initiative die dies als ein Ziel hat. Da ich gleichzeitig viel über unser Open Data Projekt gegrübelt habe, ist mir eine Parallele aufgefallen, die ich hier etwas ausbreiten möchte.
Bereits bei der Projektvorstellung kamen Fragen dazu, und ich nehme an, dass Open Data Portale sich häufig Fragen stellen müssen welche Anwender was mit diesen Daten tun werden. Diese Fragen haben natürlich ihre Berechtigung, lösen bei mir aber oft den Impuls aus den anderen Aspekt von “Open” in Open Data verteidigen zu wollen. Ich finde Open geht nicht nur um die Bereitstellung von öffentlichen Daten bzw. die Öffnung bisher verschlossener Datensätze – es geht auch um Open hinsichtlich möglicher Verwendungen. Projekt-Verantwortliche, Plattform-Betreibende und Datenbereitsteller sollten niemals eine abschließende Liste möglicher Verwendung der Daten im Kopf haben und stattdessen alles darauf ausrichten überrascht zu werden von unerwarteten Verwendungen die sie niemals hätten antizipieren können. Und dabei meine ich nicht so kleine Sprünge wie: “Oh, das ist ja unerwartet das neben der Immobilienbranche unsere Daten auch in der Schrebergarten-Szene verwendet werden” sondern mehr sowas wie “Oh, wie cool das unsere Berliner Baumbestandsdaten zur Entwicklung neuer Organismen für die Reise zum Mars beigetragen haben und außerdem die Entwicklung eines Covid-Impfstoffs beschleunigt haben”. Und selbst das ist noch zu klein gedacht weil es nur jetzt gerade am technischen Horizont schimmert, aber Jahrzehnte später wird die Front der Möglichkeiten eine ganz andere sein. Wie dem auch sei, ich will damit das Mindset um Open Data herum ansprechen. Wenn wir an unsere eigenen Biographien denken, gibt es sicherlich viele Beispiele, wo bestimmte Erlebnisse aus der Kindheit zum Schlüssel für spätere Karriereentscheidungen wurden. Damals lies sich unmöglich vorhersagen das der beiläufige Kommentar meiner Großmutter beim Spaziergang mich Jahre später dazu bewegt hat dieses Studium zu wählen. Eltern investieren so viel Liebe, Zeit und Aufmerksamkeit in ihre Kinder, idealerweise ohne festgelegt zu haben wie deren Leben sich entfalten wird. Ich fände es toll wenn sich bei mehr Menschen die in Positionen sind Daten in den Händen zu haben die sie dann veröffentlichen könnten ein Gefühl einstellt von: “Keine Ahnung was jemand damit machen könnte, aber das fühlt sich nach etwas an, das ich zur Verfügung stellen möchte.” Wie so ein Automatismus, man würde quasi ganz intrinsisch ein schlechtes Gewissen wenn man den Raum der Möglichkeiten um diese Datenquelle betrügen würde. Der Outside-In Effekt ist auch super spannend und wurde schon erwähnt in unserer Onboarding Woche. Wenn die öffentliche Verwaltung Daten öffentlich macht, ist natürlich auch für alle Mitarbeiter im selben Ministerium klar, dass sie diese Daten nutzen dürfen. Einfacher zu finden ebenso, nämlich genau da wo sie jeder finden kann. Eine teilweise veröffentlichte Auslagerung der eigenen Bestände. Ich stelle mir vor, dass das auch interessante organisationskulturelle Effekte mit sich zieht. Weniger Geheimnisse, näher am Bürger durch Zugriff auf die gleichen Daten, ein Streamlining hin zu einer Pipeline im Sinne: wir haben alle die gleiche Datengrundlage zur Verfügung und in diesen Strom klinken wir uns jetzt ein als Behörde durch gewissenhafte Verarbeitung dieser Daten und das Treffen von Entscheidungen basierend darauf.
Nun die Verbindung zum Wandel in der öffentlichen Verwaltung. Ich würde sagen, es geht um das Einlassen auf zielorientierte Suchprozesse statt dem Marschieren entlang linear geplanter Pfade hin zu fixen Zielen. Aber warum ist das “auf einmal” so? Die Zunahme der Komplexität in der Welt ist die offensichtliche Antwort. Dinge sind viel mehr in Bewegung als noch vor einem Jahrhundert. Das waren sie sicher schon immer, aber damals eben langsam genug, als das Korridore von der Gegenwart in eine geplante Zukunft lange genug offen gehalten werden konnte um sie per Projektmanagement durchschreiten zu können. War das Ziel erreicht, konnte es lange genug verteidigt werden als neuer Stand der Dinge, als das sich der Aufwand gelohnt hat. Mittlerweile bewegt sich alles so schnell das agile Prozesse die angemessene Vorgehensweise sind. Und ist ein Ziel einmal erreicht, geht es um kontinuierliche Weiterentwicklung. Die Community um ein Open Source Projekt herum bspw. ist mittlerweile absolut entscheidend um die zu erwartende Langlebigkeit von einem Stück Software zu beurteilen. Das dies für die öffentliche Verwaltung in mehrfacher Hinsicht eine Herausforderung ist, verstehe ich total. Das ganze System ist auf Verlässlichkeit ausgelegt und hat entsprechend das Mindset seiner Mitarbeiter geformt. Zudem erwarten die meisten Bürger verlässliche und objektive Antworten und Lösungen vom Staat. Sicherlich zu Recht – ich bin sehr gespannt wie sich hier also beiderseitig Verständnis und Akzeptanz von agilen und iterativen Prozessen schaffen lässt.
Die Parallele zu Open Data ist, dass es in beiden Fällen um eine Ergebnisoffenheit geht, die vorher nur bedingt da war und zunehmend wichtiger und angemessener wird. An der Stelle wird es dann eben auch sehr persönlich. Wie geht es Menschen wenn sie mit unsicheren Ausgängen konfrontiert sind? Für einige mag dies aufregend sein während es sich für andere schlimm anfühlt. Die Kunst in der Staatsarchitektur hier ist, denke ich, Grundsicherheiten zu schaffen in denen man sich zuversichtlich einlassen kann auf Unsicherheiten. Sozialstaaten sind hier natürlich sehr viel besser positioniert als Staaten bspw. ohne Krankenversicherung. Wie soll man kognitive Kapazitäten für ergebnisoffene Prozesse mitbringen wenn jederzeit die Gefahr droht durch eine Krankheit oder einen verloren Job in Existenznot zu geraten. Und wenn man sich dem potentiellen Impact eines ergebnisoffenen Prozesses vorstellt – lässt man es zu, dass etwas über den eigenen Horizont hinauswachsen kann? Was wenn das Ergebnis ist, dass wir unsere Organisationseinheit auflösen sollten? Was wenn wir zu Einsichten kommen die zum Wohle aller aber zu meinem Nachteil sind? Hier ist auch wieder das Gefühl sehr wichtig in einer Ökonomie unterwegs zu sein, die Alternativen bietet und einen nicht im Regen steht lässt.
Ein guter Trick ist sicher auch, Methoden und Toolkits zu entwickeln und sie immer präsenter werden zu lassen, dann kann die Methodik des ergebnisoffenen Prozess zum stabilen Ankerpunkt werden wenn es deren Inhalte nicht sein können. “Alle machen jetzt Design Thinking und erzielen tolle Ergebnisse, dann kann es so nicht so falsch sein”. Ich würde aber sagen, letztendlich geht es aber immer darum, Unsicherheit lange genug aushalten zu können, bis sich etwas neues sinnvolles präsentieren kann. Und das auszuhalten kann unangenehm sein. Ich bin kein Psychologe, weiß aber das ich an meinen weniger extrovertierten Tagen Kaffeepausen ganz schlimm finde weil es völlig ungeregelt ist wer mit wem über was spricht. Ab wann ist es ok wenn ich ein Grüppchen verlasse, brauch ich immer einen guten Grund (auf’s Klo, nach Hause…) oder ist die Lust auf ein neues Grüppchen ausreichend. Das nimmt dann natürlich ab mit der Zeit: man lernt die Leute kennen, hat mehr als genug Gesprächsmaterial usw. Hier also community building als Maßnahme Unsicherheitsräume aushaltbar und eben sogar erfrischend und inspirierend zu gestalten. Die Balance von genügend Vorhersagbarkeit gepaart mit genügend Neuem.
Viele Stränge passieren in diese Überlegung denke ich. Das Finance 4.0 Projekt in dem ich in meinem vorigen Job als Blockchain Developer gearbeitet habe war bspw. zu meiner großen Freude sehr stark von Emergenz-Offenheit geprägt. Welche Tokens auf der Plattform Traktion entfalten, welche Beweisführungen dabei die Balance zwischen Sicherheit und Bequemlichkeit meisten, welche Ökosysteme sich um Tokens herum entfalten… an vielen Stellen haben wir aktiv darauf gesetzt nur das minimal nötige vorzugeben und den weiteren Verlauf der Community zu überlassen. Überlegungen die dann in Themen wie Decentralized Autonomous Organizations (DAO) auf spannende Spitzen getrieben werden. Oder App Stores – auch ganz klar die Einsicht das eine große Organisation niemals tolle Apps für alle Anwendungsfälle bauen kann und sie so massiv attraktiv für Entwickler werden wollen. Ich fand diese Stelle aus Lisa’s Blogpost dazu auch super passend: “It became more about what a specific person can bring to the table rather than what their role was”. Hier also auch hin zur Frage was können wir zusammen tun jetzt wo wir zu einem Team zusammengewachsen sind. Auf welche Prozesse können wir uns einlassen jetzt wo wir die Unsicherheiten kalibriert haben auf eine Balance zwischen Vorhersagbarkeit und Neuem.
Als Fazit würde ich sagen, es geht um verschiedenste Strategien Unsicherheiten auszuhalten: persönlicher wie organisationaler Natur. Und darum Emergenz by Design zu kultivieren. Ich bin super gespannt wie das weitergeht. Mit einer immer weiter zunehmenden Weltkomplexität, was kommt nach agil was noch besser mit dieser Dynamik umgehen kann? Oder ändert sich was in unseren System und Wahrnehmungen das es nicht mehr alles so komplex wirkt? Die Auslagerung von Komplexität in dezentrale System als eine Möglichkeit zentrale Verwaltungsapparate zu entlasten?
Update: Ontologies & Blockchain
Long time no posting! I’d like to write about two updates since my last post here in 2018: my Master’s thesis at fortiss and my work as blockchain developer for ETH Zürich.
Ontologies
My thesis is meanwhile published here. It was a great foray into the world of ontologies and semantic reasoning. One that will certainly inform my coding and thinking from now on, maybe also my career choices. In short, it was about matching the capabilities of a robotic gripper with the geometric conditions of an object.
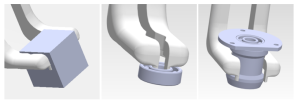
The gripper in this screenshot for instance has a few options how to grab different objects. In classical motion planning, millions of possible grasping approaches would be computed to find the few feasible ones. The interesting part about leveraging geometrical data to a semantic level, is, that it can be reasoned with. With a few queries the software can “reason” about grasping options. Just like we would intuitively know how to grasp objects with our hand. What I like about reasoning with ontologies as a way to comb through data in contrast to (most) machine learning approaches is, that backtracking is always possible. It makes rarely sense to “ask” a neural net how a certain outcome came to be. A semantic reasoning system however, always offers perfect insights into its workings. A memorable example that my thesis advisor gave me in the beginning was, that once we are able to reason about what a gripper can do with an object, we could just as well reverse the queries and ask how a new gripper might look like that is optimised for grasping a set of certain objects. From my experience of expanding the ontology of fortiss with these capabilities, I gained a huge respect of the power these approaches can hold. The laborious process of designing ontologies pays back abundantly through the many obvious as well as unforeseen ways it can bring added value.
Blockchain
My curiosity about the blockchain space was building up via the ZigZag podcast, Munich Legal Tech events and other sources. When I saw a seminar at TU Munich about it, I signed up despite not getting credit points for it in my Masters. In this seminar, among others, Dr. Marcus Dapp from the chair of Computational Social Science at ETH Zurich offered a project related to his research project “Finance 4.0“. After our team assignment was done in the summer semester 2019, I continued working on it under ETH-employment: four months living in Zurich and then from the beginning of 2020 to the (preliminary) end in July remotely from Munich. It was a very steep learning curve and I enjoyed it a lot. Getting into a new technology from scratch more or less by my own helped building confidence.  The basic idea of Fin4 is to foster positive sustainable actions, be it in ecological or social space. Anyone can create “currencies”, called tokens, using our decentralized app (dApp). I could create a “Clean the Isar token” that can be claimed by providing photo-proof of a cleanup action. If people are interested in claiming this token depends what kind of ecosystem emerges around it. The city of Munich could decide to waive some amount of taxes in exchange for sustainability tokens claimed by citizens. And maybe I can trade my Isar tokens with some Spree tokens when I move to Berlin. The idea is, that by enabling currencies to spawn on any level of granularity instead of just one big Euro or one big Dollar, a multitude of “economic currents” (see the similarity to “currency”) can be incentivized that were previously hardly visible or entirely inaccessible. Local actors anywhere can start building ecosystems of tokens around needs they see in their communities for fostering sustainability or social cohesion. Among the first questions people have about the project is: why blockchain? While I wouldn’t answer this question in the affirmative for a lot of blockchain projects out there, I would definitely do so for the Fin4 project. I would say it’s a perfect ideological match. Let’s say a major in a small village in Italy wants to incentivize the farmers in his village to use less water on their fields. The project has a timespan of 10 years. With a centralized Fin4 architecture he would have to trust the ETH Zurich to keep the servers and the database running for that time and not to tamper with the data. But with the decentralized architecture we chose by making it a dApp on the blockchain (an Ethereum test network for now), he has to trust no one to keep things running. Once deployed, the smart contracts (code on the blockchain) can never be removed or tampered with. All code and all transactions are visible for everyone forever. There would be so much more to say about the project – if interested, check out the project website finfour.net that also links to an extensive eBook and a live demo that I worked on. I am grateful to have had this opportunity to deep-dive into the blockchain space with such a profoundly interesting project and feel enriched with ideas and lots of new useful skills.
The basic idea of Fin4 is to foster positive sustainable actions, be it in ecological or social space. Anyone can create “currencies”, called tokens, using our decentralized app (dApp). I could create a “Clean the Isar token” that can be claimed by providing photo-proof of a cleanup action. If people are interested in claiming this token depends what kind of ecosystem emerges around it. The city of Munich could decide to waive some amount of taxes in exchange for sustainability tokens claimed by citizens. And maybe I can trade my Isar tokens with some Spree tokens when I move to Berlin. The idea is, that by enabling currencies to spawn on any level of granularity instead of just one big Euro or one big Dollar, a multitude of “economic currents” (see the similarity to “currency”) can be incentivized that were previously hardly visible or entirely inaccessible. Local actors anywhere can start building ecosystems of tokens around needs they see in their communities for fostering sustainability or social cohesion. Among the first questions people have about the project is: why blockchain? While I wouldn’t answer this question in the affirmative for a lot of blockchain projects out there, I would definitely do so for the Fin4 project. I would say it’s a perfect ideological match. Let’s say a major in a small village in Italy wants to incentivize the farmers in his village to use less water on their fields. The project has a timespan of 10 years. With a centralized Fin4 architecture he would have to trust the ETH Zurich to keep the servers and the database running for that time and not to tamper with the data. But with the decentralized architecture we chose by making it a dApp on the blockchain (an Ethereum test network for now), he has to trust no one to keep things running. Once deployed, the smart contracts (code on the blockchain) can never be removed or tampered with. All code and all transactions are visible for everyone forever. There would be so much more to say about the project – if interested, check out the project website finfour.net that also links to an extensive eBook and a live demo that I worked on. I am grateful to have had this opportunity to deep-dive into the blockchain space with such a profoundly interesting project and feel enriched with ideas and lots of new useful skills.
